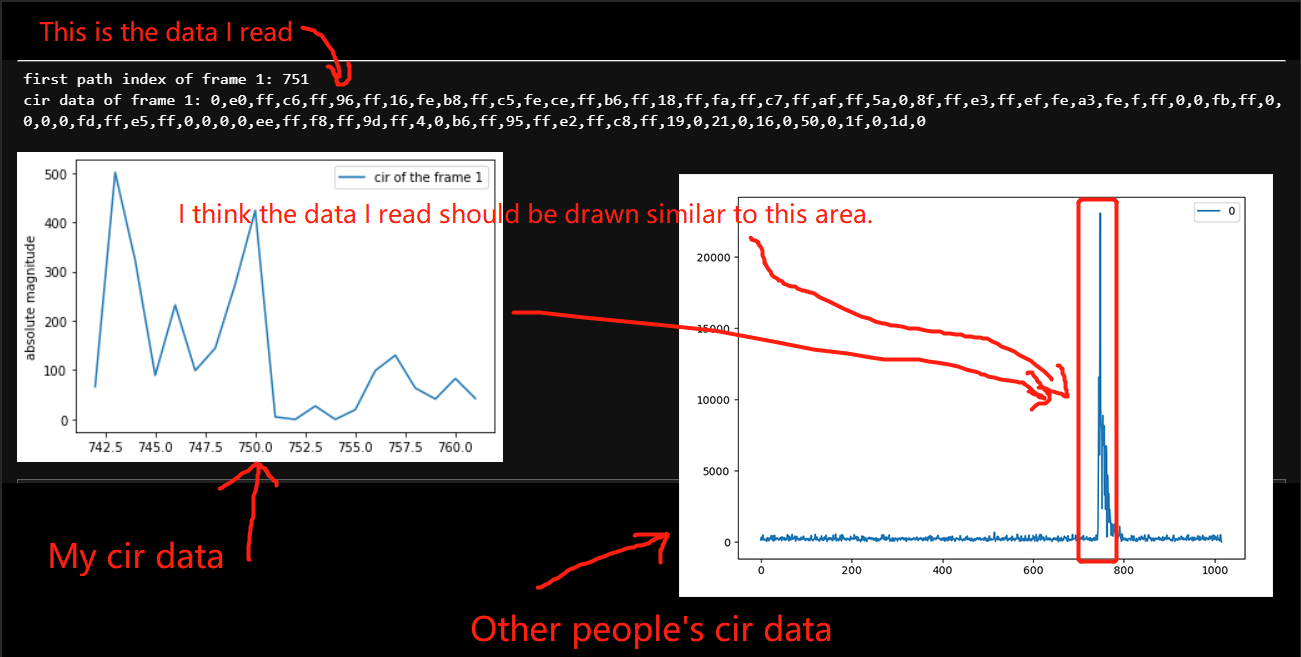
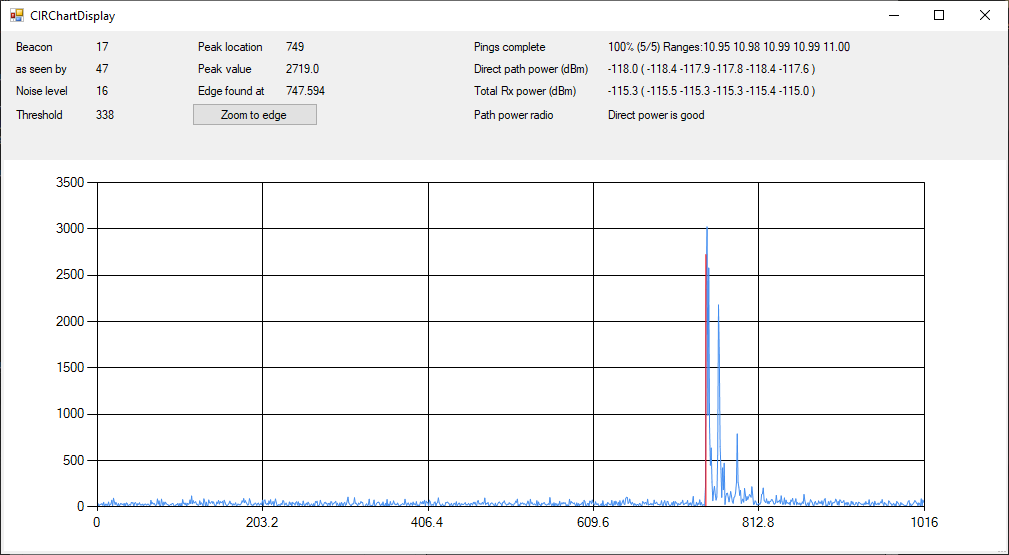
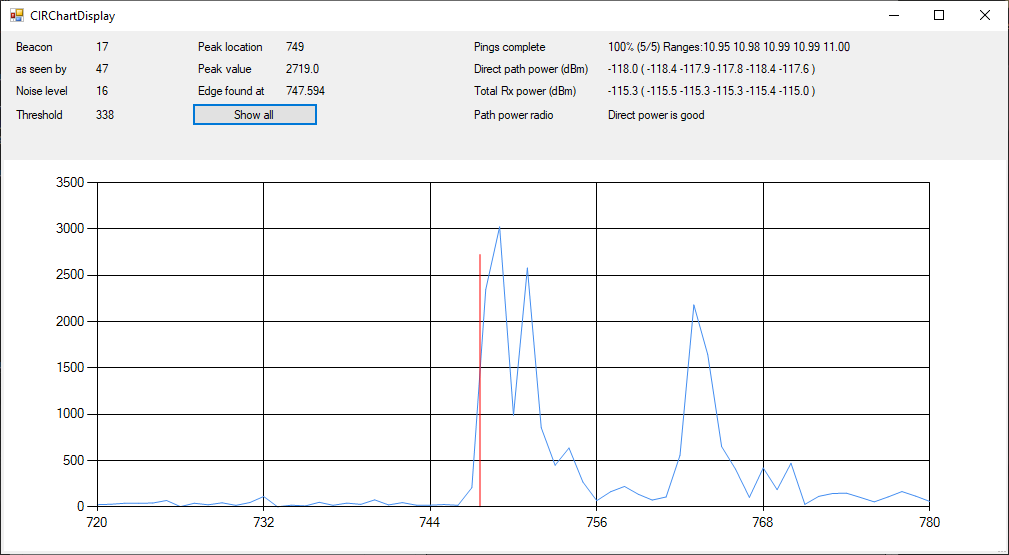
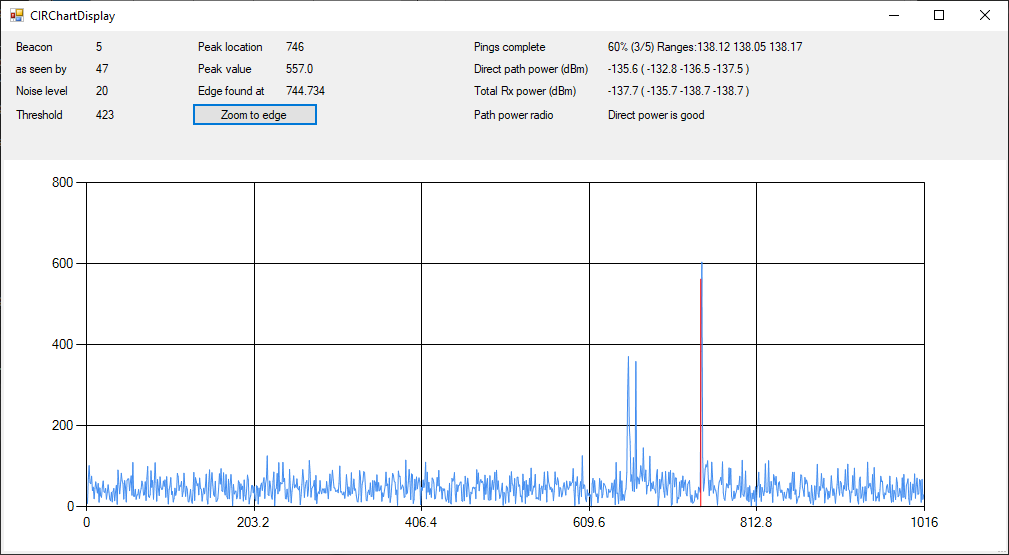
Hi everyone,
I am using a board based on dwm1000 module. I want to use the dwt_readaccdata() function reads the CIR value from the accumulator CIR memory. I imitated the example you provided, just simply read the value near FirstPathIndex.
Now I have a few questions.
- In the example,.
uint16 fp_int = rx_diag.firstPath / 64;
dwt_readaccdata(accum_data, ACCUM_DATA_LEN, (fp_int - 2) * 4);
why rx_diag.firstPath is divided by 64, not any other number? I think it is 32, because according to dw1000_user_manual 7.2.38 Register file: 0x25 – Accumulator CIR memory, every 32bits is a sample.
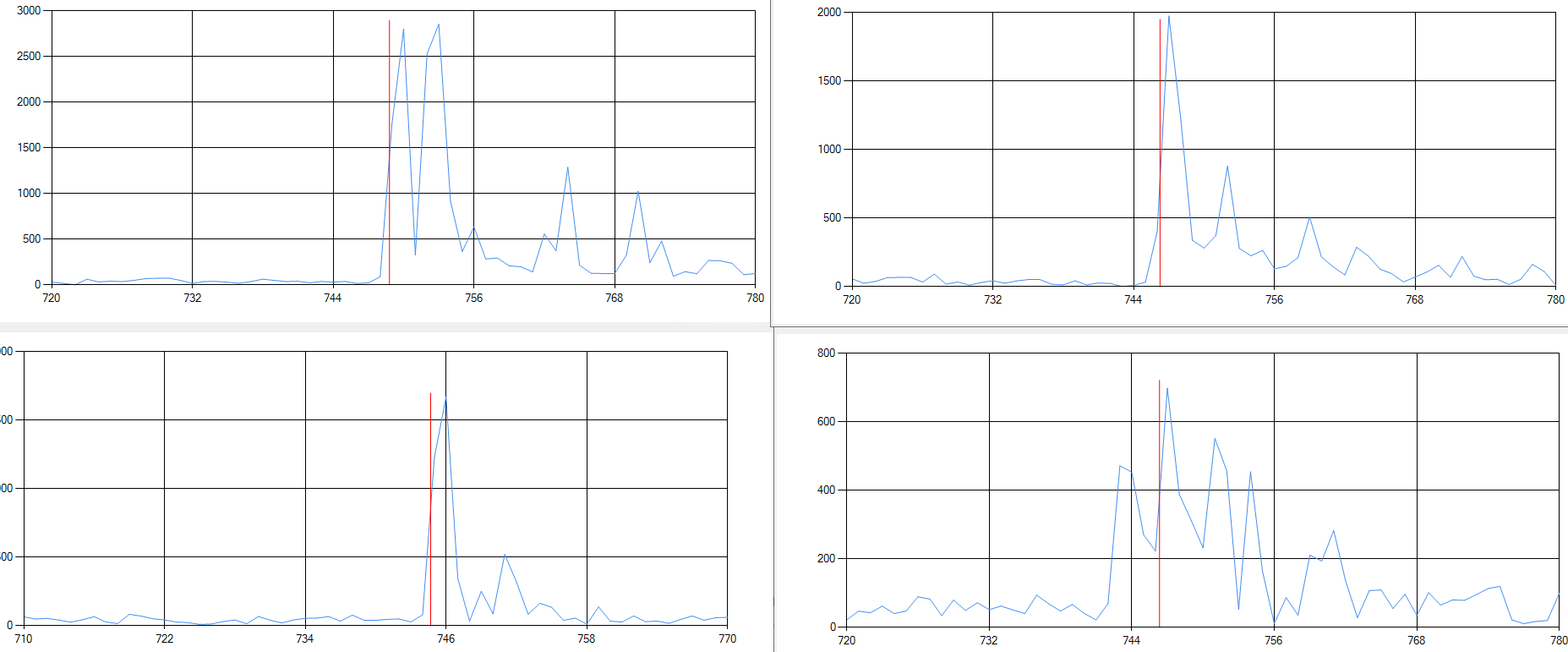
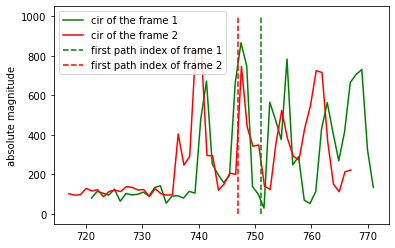
2.I imitated the code in example to write the program, but got a strange CIR value. I will write my code and the CIR value I read.
int FirstPathIndex = 0;
uint8 CIR_data[25];
dwt_readdignostics(diagnostics);
uint16 fp_int = FirstPathIndex / 64;
dwt_readaccdata(CIR_data, 25, (fp_int - 2) * 4);
m = sprintf((char*)&usbVCOMout_CIR[0], "CIR:%d, %d, %d, %d, %d, %d, %d, %d, %d, %d, ",
CIR_data[0],CIR_data[1],CIR_data[2],CIR_data[3],CIR_data[4],
CIR_data[5],CIR_data[6],CIR_data[7],CIR_data[8],CIR_data[9]);
m += sprintf((char*)&usbVCOMout_CIR[m], "%d, %d, %d, %d, %d, %d, %d, %d, %d, %d, ",
CIR_data[10],CIR_data[11],CIR_data[12],CIR_data[13],CIR_data[14],
CIR_data[15],CIR_data[16],CIR_data[17],CIR_data[18],CIR_data[19]);
m += sprintf((char*)&usbVCOMout_CIR[m], "%d, %d, %d, %d, %d\r\n",
CIR_data[20],CIR_data[21],CIR_data[22],CIR_data[23],CIR_data[24]);
App_Module_Uart_USB_Send_1((uint8_t *)usbVCOMout_CIR, m);
The result read is:
CIR:0, 114, 1, 47, 254, 59, 1, 251, 253, 193, 0, 248, 254, 39, 0, 22, 0, 152, 0, 30, 255, 174, 0, 244, 253
After removing the first value and calculating the real part, imaginary part and module, it is obvious that it is wrong. For example, the real part will be 370 and the imaginary part is 65071(according to 114, 1, 47, 254)
Who can tell me where I’m wrong.