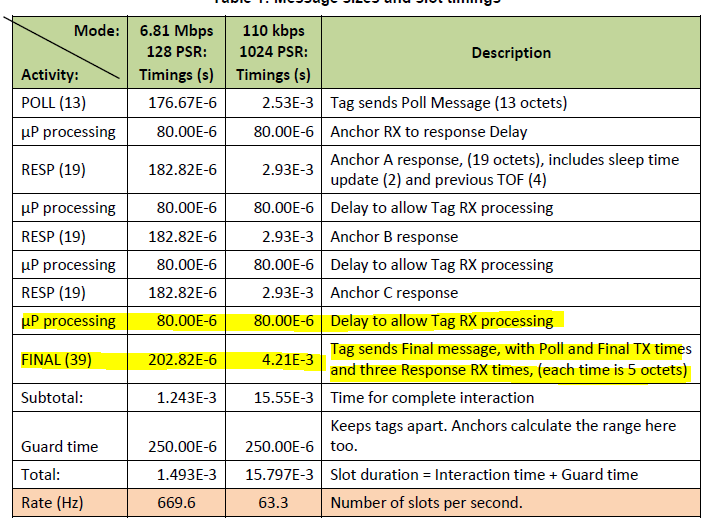
Between receiving the last anchor response and sending the FINAL message, the tag apparently needs just 80us + 202.82us (for the 6.81Mbps mode) to receive the POLL message interrupt, read the rx buffer, make some calculations, schedule the delayed transmission of the FINAL message, write the tx buffer and finally send the FINAL message. How is that possible in under 300us? I do not understand how one can schedule a delayed transmission that apparently is only a few microseconds in the future?
In “APS013” the following is stated:
The absolute minimum response time that can be achieved would be around 200 μs, this is microprocessor dependent, it depends how quickly the microprocessor can see the completion of reception and start the transmission.
I don’t know how they have implemented the details of their system but there are all sorts of tricks you could use. e.g. you could write most of the tx message into the buffer in advance. You could schedule the transmit as soon as the receive is complete and then update the last few bytes of the message data after that once you have processed the message.
You could even have decided what the transmit time for that final packet will be as soon as you have finished sending the first packet. Thinking about it if you know you have a fixed delay from that first poll to the final message then you don’t even need to send the final tx time in that packet, all points can infer that information from the initial poll tx time.
To give you an idea of what’s possible, my system doesn’t use any of those tricks. It runs a simple fill the buffer and then enable the transmit mode of operation, when not transmitting it’s sitting listening, terrible in terms of power efficiency but simple. It doesn’t even use the double buffered receive features.
UWB data is sent at 850k, I couldn’t get enough range at 6.8M.
Using this system we get 2400 ranges per second split between 8 or 12 anchors.
I suppose you do not work with the dwm1001 as I do (faster processor, faster spi)?
Using double buffering and 6.8M I am currently stuck at ~2000 ranges per second (8 anchors).
So in theory I should be able to be a lot faster even with the dwm1001…
Another question: do you use the asynchronous twr scheme, i.e. a total of n+2 uwb messages for ranging to n anchors? In this case I do not understand how you can get 2400 ranges, due to the quite long transmission time @ 850k (at least 400us per message if using a preamble length of 256 → >4ms for ranging to 8 anchors → <2000 ranges per second).
It’s a 100MHz Arm M4 with the SPI clocked at 20 MHz (the max allowed by the DW1000).
We are using a system similar to the asynchronous the n+2 approach with n=8 or 12 but with a couple of tweaks that improve performance in our use case at the cost of flexibility.
We use a short preamble and the packet size is stripped to the absolute minimum.
The timings end up being tight but we can reliably hit them.
Just for single point to point twr we managed to get it to an 800Hz measurement rate. At 6.8M we could get that up to 1 kHz but the range wasn’t enough. Or to be more accurate the range wasn’t enough once we dropped the transmit power to be within the FCC limits.