Hi,
We did other experiments in order to try explaining our problem, and I ask you to confirm our reasoning is correct.
We made a simple network with just 4 anchors (1 of which is initiator) and 1 tag, powered by battery, configured with autopositioning. The configuration was ok and the tag correctly started to trace its position in the network. At this point we tried theese experiments:
(1). We removed the battery of the initiator, expecting the network wuold have gone completely out of work, contrariwise the tag continued ranging with the other 3 anchors for some seconds, then with 2 anchors, and then just 1 anchor, but continued to receive ranging measures from the last anchor in the network also without the initiator. Shutting down the tag and restarting it, the tag effectively did not range with any anchor.
(2). We replicated the experiment (1) but removing the battery of one anchor instead of the initiator, and the network correctly continued to work as expected.
(3). We retried onother time to remove the battery of the initiator and replace it immediately, before the network went out of work. The result was that some seconds after we turn on the initiator, the network went off for some seconds (about 10 seconds) and then restarted working correctly. It looked like the initiator restarted to configure the network, and there was some delay in the communication between the nodes.
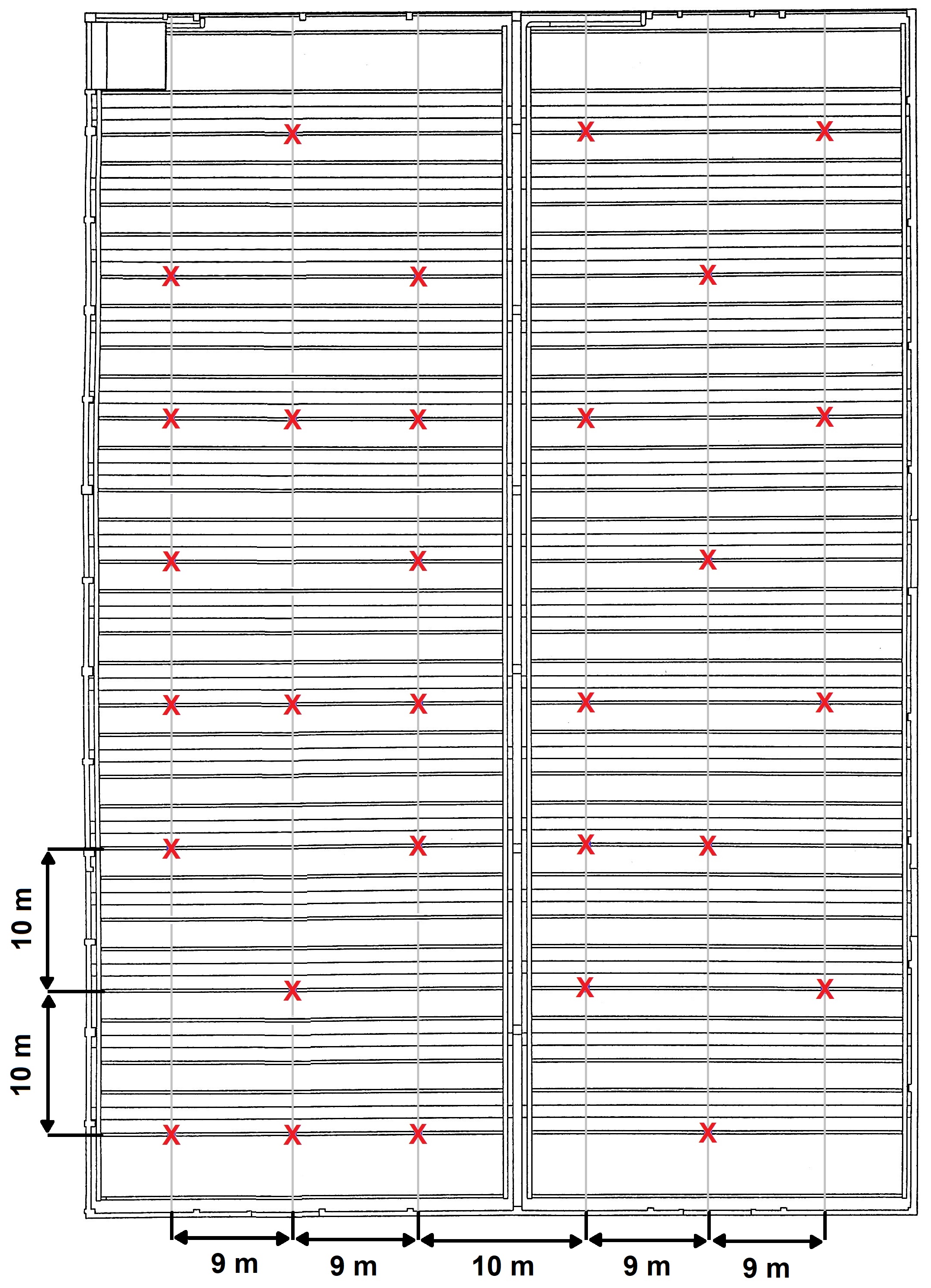
In our implementation inside the warehouse shown before, the anchors are powered by the power grid trough six independent electrical busways on the ceiling and we thougth that an unexpected instantaneous interruption of the power supply for one busway, will result in shutting down all the anchors in that busway, so if the initiator was there, the network would stop working for some seconds.
We thought that configuring the network with more initiators would be a sort of backup to prevent that issue. Do you thing that it is good for our actual network configuration in the warehouse? For example if there are 2 initiators in the network and one of them lose the power supply, the other initiator immediately takes control of the superframe or there will be the same problem due to a new network configuration?
We would have to cover a larger area of about 25.000 square meters, whith about 250 anchors and 15 tags, and we can’t afford theese kind of network interruptions. The final configuration will be the repetition of the same configuration shown previously in the pictures, replicated more times and eventually with more than one initiator if you think that precaution would fix this problem.
I keep waiting for your feedback
Thanks,
Simone